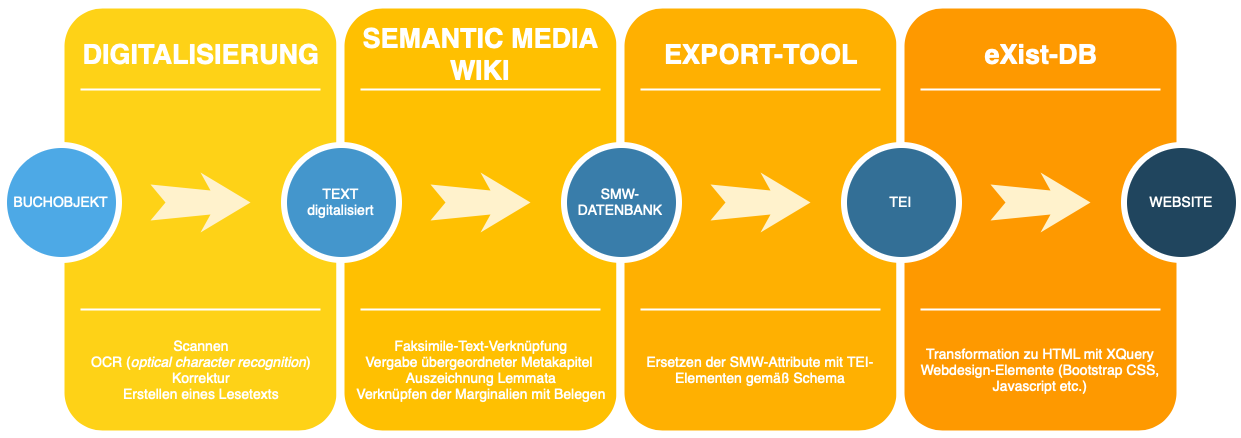
Technische Infrastruktur und Workflow
'Narragonien digital' entstand im Rahmen des Würzburger "Kallimachos"-Projekts in enger Zusammenarbeit von Kolleginnen und Kollegen der Germanistik, Romanistik, Informatik und Digital Humanities (siehe Projektgruppe). Die Webpräsentation wurde von Dominika Heublein, Yannik Herbst und Joachim Hamm erarbeitet und wird vom Zentrum für Digitalität und Philologie an der Universität Würzburg gehostet und technisch betreut (Ansprechpartner: Sina Bock, M.A.). Die digitalen Narrenschiffe sind Ergebnis eines mehrstufigen Workflows, der in weiten Teilen projektspezifisch konzipiert und durchgeführt werden musste. Denn die große Anzahl von 'Narrenschiff'-Texten und die Vielfalt des Buchlayouts und der zu bearbeitenden Sprachen ließen es nicht zu, ein Standardkonzept für digitale Editionen umzusetzen. Die vorliegende Dokumentation soll einen Einblick in die technische Umsetzung der Edition geben.